13 minutes
How I Used AI to Summarize Long-Form Podcasts into Daily Takeaways
Overview
I love learning from educational podcasts, but there’s a constant struggle: I don’t have enough time to listen to them as often as I’d like. While driving to the mountains one day with my wife, We were listening to an Andrew Huberman episode—my favorite show and the core inspiration behind this project—and I thought, “I’m gaining so many actionable insights here. It would be great if I could consume more of these, more often.” Since I can’t magically create extra hours in my day, the next best thing is to find a way to absorb the most crucial information more efficiently.. While I do believe that long-form consumption is the best way to do most things, there are times where you just really don’t have the time to do so. An example of this would be reading the Spark Notes version of a book or watching a Youtube summarization of the core concepts in a book. While this is very beneficial at times and you can still learn from it, I do not think it is a replacement for reading the actual book. I believe there is something that happens in our brain when we have to go through the whole experience of reading the book that does not take place when we just extract the main concepts from it. However, like I said, we do not always have the time to do this, hence the birth of this project.
What problem is it solving?
The main issue that this is solving is the issue of not having the time to consume the beneficial and actionable knowledge that educational podcasts give us. For example, Huberman Labs releases one podcast, every Monday, that usually spans the duration of ~3 hours. I may have 15 free minutes a day that I am not doing something that would give me time to listen to this. Breaking a 3 hour long podcast into 15-minute bytes just does not seem like the way that I would want to consume this type of information. What this more so turns into is binge listening to his podcasts when on a trip or something, and then just missing dozens of hours of these podcasts until I have another trip or something like that where I have time to listen to it again. TL;DR: I want to listen to education podcasts to learn real-life things that I can apply to my daily life, but I do not have the time to do this.
What does it do?
Here is the gist of what this does:
- Check for new content: The script looks at a specified YouTube channel to see if there’s a new podcast/video.
- If yes, it grabs that new video.
- If no, it picks a previously released one (but still one you haven’t processed before).
- Avoid duplicates: It checks all previously processed videos and skips any you’ve already worked with.
- AI-powered digestion: Using Fabric—a tool that transcribes and summarizes long-form content—the script processes the entire video. It pulls out the actionable insights, habits, facts, and key recommendations, then compiles them into a structured, easy-to-read page in your notes.
- Daily notes update: Finally, a “Daily Prophet” page in your Obsidian setup updates automatically to include these new insights right at the top, ensuring the freshest material is always front and center.
How it Looks
I have a pinned page in my notes titled “The Daily Prophet” that, in source view, just consists of the following:
!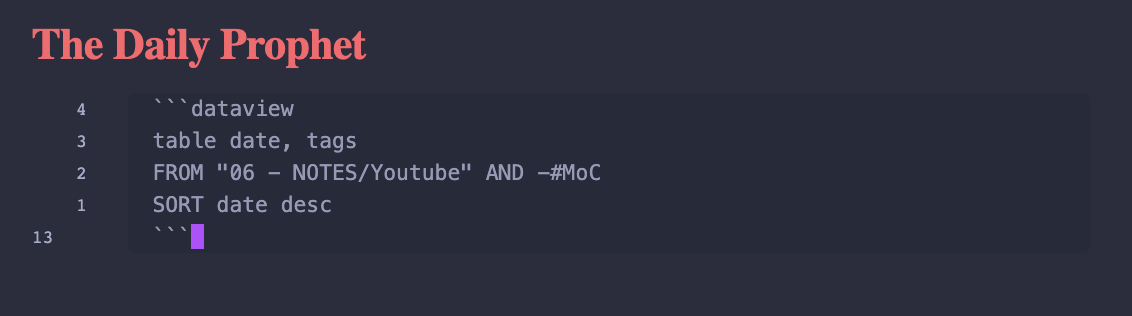 When I switch over to Reading mode however, I see the following:
When I switch over to Reading mode however, I see the following:
!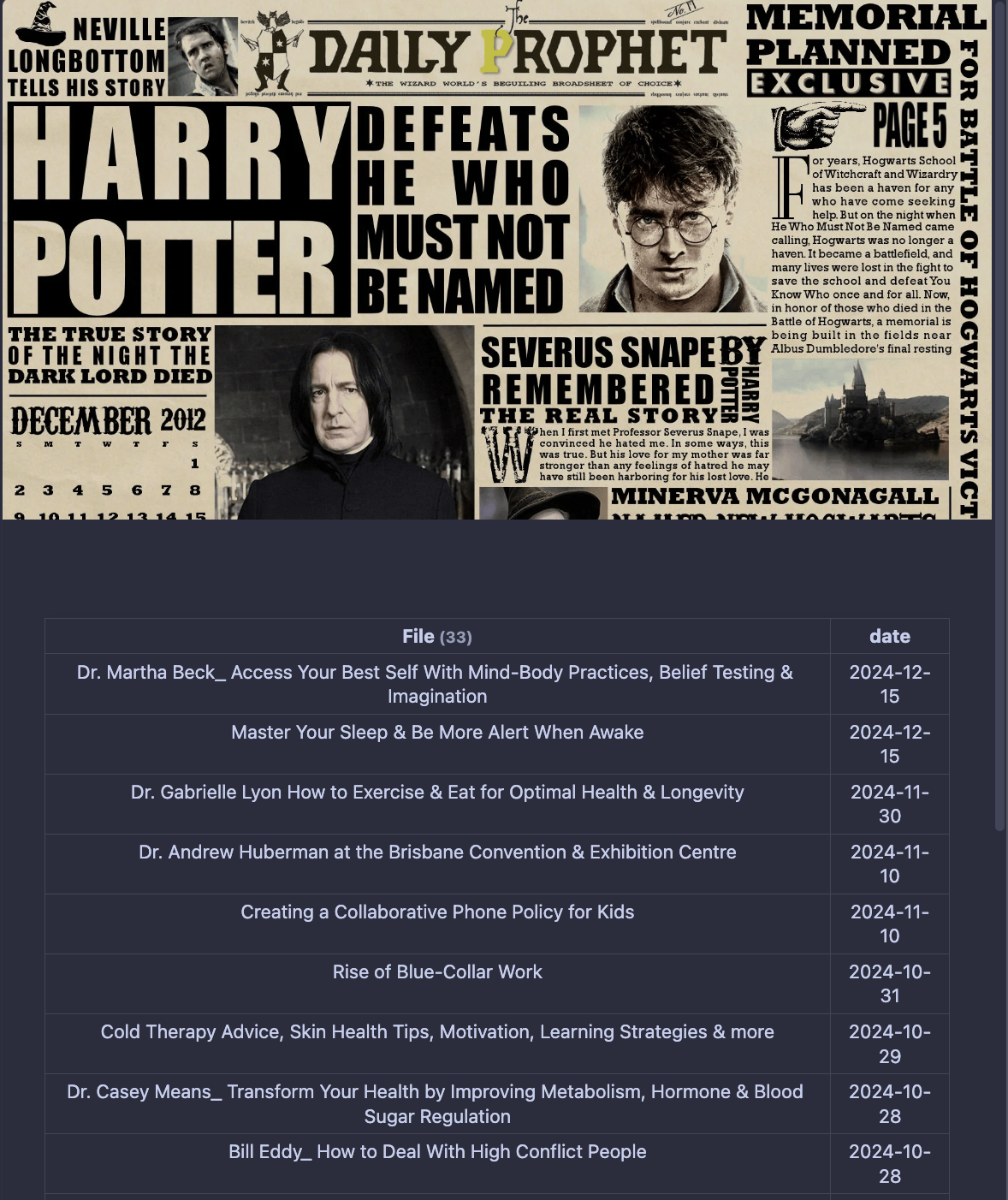
Selecting one of these generated notes shows the embedded YouTube video at the top, allowing me to watch or listen alongside the summarized notes. This way, even if I’m short on time, I can quickly review the main points first and then dive deeper into the full episode if I choose.
!
Each note includes several thoughtfully organized sections—like Summary, Ideas, Insights, Quotes, Habits, and more—making it easy to skim for what matters most. It’s not meant to replace the original content entirely, but rather to serve as a helpful guide or refresher that saves me time and helps me stay on top of valuable information I’d otherwise miss.
!
How does it work?
Here is the flow the program works in.
Scripts Overview
- main.py: This script coordinates the entire workflow. It picks a new video, runs Fabric, and then writes the processed insights into a Markdown file.
- youtube_url.py: This module handles retrieving recent videos from a specified YouTube channel using the YouTube Data API. It also ensures you don’t process the same video twice.
Note - before you run these scripts, note that you’ll need:
- A valid YouTube Data API key.
- The channel ID of the YouTube channel you’re targeting.
- A configured path to your Obsidian notes.
Breakdown
1. Get the URL
The process starts by looking up a YouTube channel for either a brand-new podcast or one you haven’t processed before. Once it finds a suitable video, it pulls its URL and checks against a file of previously used links to avoid duplicates. If it’s already been summarized, the code moves on until it finds something fresh.
From main.py:
def main():
# Step 1: Get a new or unused YouTube video URL
latest_video, video_title = get_random_video()
video_id = latest_video.split('=')[-1]
sanitized_title = sanitize_filename(video_title)
today_date = datetime.today().strftime("%Y-%m-%d")
file_name = f"{NOTES_PATH}/{sanitized_title}.md"
iframe_code = f'<iframe width="560" height="315" src="https://www.youtube.com/embed/{video_id}" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>'
From youtube_url.py:
def get_random_video():
"""Find a random video that hasn't been used, with minimized API calls."""
used_urls = get_used_urls()
all_videos = []
# Fetch and store videos from multiple pages, if needed
page_token = None
while len(all_videos) < 50: # Limit to prevent too many requests
video_info = fetch_videos(page_token)
videos = [
(
f"https://www.youtube.com/watch?v={item['id']['videoId']}",
item['snippet']['title']
)
for item in video_info.get("items", [])
if "videoId" in item["id"]
]
all_videos.extend(videos)
# Check if there’s another page available
page_token = video_info.get("nextPageToken")
if not page_token: # Stop if no more pages
break
# Shuffle videos to pick a random one
random.shuffle(all_videos)
# Look for a new video in the cache
for video_url, video_title in all_videos:
if video_url not in used_urls:
add_url_to_used(video_url)
return video_url, video_title
# If no new videos found after checking all, return None or a message
return None, "No new videos available."
2. Run the extraction/digest
The heart of the script is this following line. This is what is doing all of the work and all of the thinking. This open-source tool, Fabric, was created by Daniel Miessler, and is amazing and I use it for so many of my projects. Here is a link to it if you are interested, and I would highly recommend you checking it out. The quick and dirty summary of this tool, as quoted from the the README.md of this repo, is that:
fabricis an open-source framework for augmenting humans using AI.- Since the start of 2023 and GenAI we’ve seen a massive number of AI applications for accomplishing tasks. It’s powerful, but it’s not easy to integrate this functionality into our lives.
- In other words, AI doesn’t have a capabilities problem—it has an integration problem.
- Fabric was created to address this by enabling everyone to granularly apply AI to everyday challenges.
Here is what the command that this script is using looks like:
command = f"fabric -y {latest_video} -p extract_wisdom"
Here is what this is doing in a nutshell:
- Fabric grabs the URL from the video we found earlier
- It transcribes it
- An AI model of your choosing, ChatGPT-4o in my case, is primed with a pattern that you specify. This pattern shown above it called
extract_wisdon. What this does is primes the AI model with a set of instructions on how to handle the input that is coming, in this case, the youtube transcription. Check out what that pattern actually looks like here. I created a few custom ones when building this project, but none of them came out as good as this one, so I just went ahead and used this default pattern included with Fabric. - The transcription is sent through the primed AI model and Fabric outputs the response.
3. Save the output to my Obsidian notes
A new file is created and formatted. To summarize this here, there are 3 things being written to this newly created file:
- The YAML front matter that has the date included. This is so that my Dataview table will always show the most recent at the top.
- The Youtube video is embedded at the top as seen earlier
- The output that was just created by Fabric is saved after that
with open(file_name, "w") as f:
f.write(f"---\ndate: {today_date}\n---\n")
f.write(f"{iframe_code}\n\n")
f.write(result.stdout.decode("utf-8"))
And that’s it! Now I have all of the most useful information and actionable insights from the podcasts that I enjoy to listen to, and it is condensed into a 5-10 minute read, which is much more doable in my current schedule than listening to the upwards of 3-hour long podcast.
Future Improvements
- Refactoring and Code Cleanup: This project was actually built a several months ago, and while it works, there are plenty of opportunities for cleaner, more efficient code. Revisiting the logic and structure could make it more elegant and easier for others to understand or build upon.
- Note -> while a few months ago doesn’t seem that long ago, I didn’t pick up Python programming until June of this year (2024), so a few months ago is a world of difference here
- Automated Scheduling: Instead of manually running
python3 main.py, this entire process could be automated. Setting up a daily cron job,systemdtimer, orlaunchdjob would allow the script to run at regular intervals without any manual intervention. I’ve tested this a bit with a few of these methods and just haven’t found a good way to do this yet. The main issue here was that I used to store these notes in my iCloud library, which made running a Linux job to do this difficult with it’s lack of integration with iCloud (in terms of mounting the directory at least). Now I use Obsidian SYNC, so I may revisit this soon for a good solution. - Scalable Data Storage: Currently, used URLs are tracked in a text file. Migrating this data to a SQLite database (or similar) would be a more scalable and maintainable approach as the project grows.
Supporting Documentation
References:
Scripts
main.py
Key points:
- Fetches a fresh video and title.
- Sanitizes the title for safe file naming.
- Uses Fabric to transcribe and summarize the video according to the
extract_wisdompattern. - Creates a Markdown file with the current date, the embedded video, and the AI-generated insights.
from youtube_url import get_random_video
import subprocess
import re
from datetime import datetime
NOTES_PATH = "{PATH/TO/YOUR/NOTES}"
def sanitize_filename(filename):
"""Replace any invalid filename characters with underscores to ensure the file name is safe."""
return re.sub(r'[\\/*?:"<>|]', "_", filename)
def main():
# Step 1: Retrieve a random or unused YouTube video URL and its title
latest_video, video_title = get_random_video()
# Extract the video ID by splitting the URL at '=' and taking the last part
video_id = latest_video.split('=')[-1]
# Sanitize the video title so it can be used as a safe filename
sanitized_title = sanitize_filename(video_title)
# Get today's date in the format YYYY-MM-DD
today_date = datetime.today().strftime("%Y-%m-%d")
# Set the output markdown file path using the sanitized title
file_name = f"{NOTES_PATH}/{sanitized_title}.md"
# Create an iframe embed code for the YouTube video using the extracted video ID
iframe_code = f'<iframe width="560" height="315" src="https://www.youtube.com/embed/{video_id}" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>'
# Command to run an external process (fabric) to extract "wisdom" from the video
# `-y` it used to transcribe the Youtube video and `-p` specifies which Fabric pattern you are wanting to use
# `extract_wisdom` is the pattern specified. This is a default pattern included in Fabric
command = f"fabric -y {latest_video} -p extract_wisdom"
try:
# Execute the external command with `subprocess.run()`
# `check=True` will raise CalledProcessError if the command fails
# `stdout` and `stderr` are captured for further processing
result = subprocess.run(
command,
shell=True,
check=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
# Open the markdown file and write the date, iframe, and the extracted wisdom
with open(file_name, "w") as f:
# Write metadata (date) as front matter in YAML format
f.write(f"---\ndate: {today_date}\n---\n")
# Write the iframe code for the video
f.write(f"{iframe_code}\n\n")
# Write the output from the subprocess (decoded from bytes to UTF-8 string)
f.write(result.stdout.decode("utf-8"))
# Print a success message if everything went fine
print(f"Output successfully written to {file_name}")
except subprocess.CalledProcessError as e:
# If there's an error running the external command, print the error message
print(f"Error executing command: {e}")
# Also print the standard error output for debugging
print(f"Standard error: {e.stderr.decode('utf-8')}")
if __name__ == "__main__":
main()
youtube_url.py
Key points:
- Uses the YouTube Data API to fetch videos from a channel.
- Checks against a
used_urls.txtfile to avoid repeats. - Returns a fresh, unused video URL and title.
import requests
import random
import os
# API key for accessing the YouTube Data API.
# Note: This is just an example key, it might need to be replaced with a valid one.
API_KEY = "{INSERT API KEY}"
HMAN_CHANNEL_ID = "{CHANNEL ID}" # Channel ID for the target YouTube channel, which is Huberman Labs in this case
USED_URLS_FILE = "used_urls.txt" # File to keep track of which videos have been used
def get_used_urls():
"""Read the file containing previously used video URLs and return them as a set for quick lookups."""
if not os.path.exists(USED_URLS_FILE):
# If the file doesn't exist yet, return an empty set.
return set()
# Open and read each line, stripping whitespace. Store these URLs in a set.
with open(USED_URLS_FILE, "r") as file:
return set(line.strip() for line in file if line.strip())
def add_url_to_used(video_url):
"""Append a newly used video URL to the used_urls.txt file so it won't be selected again."""
with open(USED_URLS_FILE, "a") as file:
file.write(video_url + "\n")
def fetch_videos(page_token=None):
"""
Fetch a batch of videos from the YouTube channel using the YouTube Data API.
- page_token (optional): A token that allows pagination through multiple pages of results.
"""
# Construct the URL for the YouTube API request.
# - key: our API_KEY
# - channelId: The target channel we want videos from
# - part=snippet,id: We want snippet and id information about the videos
# - order=date: Sort videos by their upload date
# - maxResults=5: Get 5 results per request
url = (
f"https://www.googleapis.com/youtube/v3/search?key={API_KEY}"
f"&channelId={HMAN_CHANNEL_ID}&part=snippet,id"
f"&order=date&maxResults=5"
)
# If a page_token is provided, append it to fetch the next page of results.
if page_token:
url += f"&pageToken={page_token}"
response = requests.get(url)
# Raise an HTTPError if the request was unsuccessful.
response.raise_for_status()
return response.json()
def get_random_video():
"""
Return a random unused video from the channel.
Minimizes API calls by caching multiple results and only making more requests if needed.
"""
used_urls = get_used_urls() # Get all previously used URLs
all_videos = []
page_token = None
# Loop until we have fetched a good number of videos (50 as a limit here)
# or run out of pages.
while len(all_videos) < 50:
video_info = fetch_videos(page_token)
# Extract video URL and title for items that are actual videos
videos = [
(
f"https://www.youtube.com/watch?v={item['id']['videoId']}",
item['snippet']['title']
)
for item in video_info.get("items", [])
if "videoId" in item["id"] # Ensure the item is indeed a video.
]
all_videos.extend(videos)
# Check if there is another page of results.
page_token = video_info.get("nextPageToken")
if not page_token:
# If no more pages, stop fetching further.
break
# Shuffle the videos so we randomly select one each time.
random.shuffle(all_videos)
# Select the first video that isn't already in the used list.
for video_url, video_title in all_videos:
if video_url not in used_urls:
# Mark this video as used so it's not chosen again.
add_url_to_used(video_url)
return video_url, video_title
# If no new video is found, return None and a message.
return None, "No new videos available."
2629 Words
2024-12-14 19:00